Building datasets from video collections using local & cloud LLMs
Using Qwen2.5-VL, Gemini 2.5 and Whisper to build a Siskel and Ebert dataset
Jul 30 2025

Intro
I continue to experiment with LLM models finding very narrow tasks in my domain of cultural heritage where they could be useful and appropriate. I’m not going to go into it in this post but I find most pro-“AI” claims, discourse, and use cases to be completely overhyped and seem to originate from dishonest intentions. Yet for some tasks they are potentially useful, I say potentially because whether they should be used at all is another parallel question. I’m trying to understand if they are truly useful and for what specific tasks.
One area I wanted to try them on, especially now that mutli-modal models are very common, is extracting information from digital assets and collections. There are a lot of examples of things like automated image classification but I’m thinking more in terms of workflow automation or dataset creation.
Siskel and Ebert?
There are a number of legit Library of Congress collections I was thinking of using but then I came across this spreadsheet of movies reviewed by Siskle and Ebert which contained links to the video of their TV show usually hosted on YouTube. I remember their show growing up, usually playing on my Aunt’s tiny kitchen TV on the weekend, mostly as background noise. But I was thinking, would it be possible to extract their iconic thumbs up/down summary review image from these videos? This seems trivial but it is deceptively complicated:
- The summary portion of the show, where they recap what they said for each movie occurs at some point “near the end” of the show. Some of these videos linked have commercials or have been edited for YouTube, so “near the end” is not a timestamp or reliably the same each time.
- They rapidfire go through each movie spending 5-30 seconds on each film, they are back to back so you would need to correctly capture the seconds that matches to the movie you were looking for.
- The summary graphic they put on the screen will look different for each movie (there is a videoclip playing in it) and it has also changed visually throughout the different iterations of their show.
These summary card graphics looked like this:




These are problems I of course came across while attempting it. At that moment I just thought “that would be cool…” and then became obsessed with it for a few evenings. Doing complicated computer stuff for something pretty dumb is a trap it seems I can’t resist. But there are analogues to “serious” problems that could be applied to it if it worked. I mostly thought it would be a good test case to see if these tools could actually be useful for such a problem.
I ended up attempting a couple different approaches, but they all relied on having the videos and a transcript of the episodes available to process.
- Using the spreadsheet for the URLs I downloaded all the videos using the yt-dlp command line tool using this script.
- Once all the files, about 1160 where downloaded I transcribed them using Whisper.cpp using this script. It’s important to have timestamps, so make sure to get a format like VTT.
Since frontier models like Gemini can accept video I did try sending a full video to try to process to ask prompts against it but it never worked, either it timed out or I would get a content warning error and would refuse to process it.
My next strategy was to send the full transcript to Gemini and have it report back the different movies talked about in that video and the timestamps where they began the discussion about it and then the timestamp of where they summarized their review in the end of the show recap. I also asked for some other metadata, you can see the script that does this and the prompt here.
See an example of the data returned:
I was pretty surprised at how well it was seemingly able to do this. It could correctly identify the movies discussed, and most times assigned the director, the timestamp in the show when they started talking about it, the thumbs up/down for each host, and other metadata. However I think the nature of how this data is generated, via Whisper, which breaks text up contextually prevents having exact timestamp for the final summary discussion. Often the final summary would be the same timestamp for multiple movies. This points to either the transcript text is not detailed enough to identify events in the video that happen in such a small timeframe. This was also not going to work because we are concerned with what is on the screen and the timestamp being returned is based on the dialog of the hosts. So it really is not a good approach to try to pull a single frame from a 30 minute long show based on the dialog.
‼️ Takeaway: Frontier models like Gemini can successfully process and return metadata and timestamp events based on a Whisper generated transcript.
Another issue I found was that they talked about other movies in their show other than the main movies that would end up getting a thumbs up or down. For example they often had a “dog of the week” segment where they talked about a movie they thought was terrible. So there would be extra movies in the metadata returned than there would be final cards. If I could identify the cards then this problem would sort itself out because there wouldn’t be a summary thumbs up/down card for any movie that wasn’t properly reviewed.
I also found that relying on the original dataset spreadsheet as a source of truth can lead to issues. In this case you have a pile of media and a dataset that may or may not describe their contents. I found lots of cases where there were more movies discussed in an episode than the spreadsheet says. This is the worst case scenario from a data perspective where I’m using unverified data from the internet and unknown YouTube media. I think if I ever was in this situation again I would ignore the dataset at first (except for the youtube links, which were invaluable) and build a ground truth based off the LLM processed transcripts and then reconcile to the dataset to match on any important metadata it contained.
Without being able to rely on the transcript to identify the review graphics I turned to looking at the actual video frames to identify them for each movie. This is where the mutli-modal aspect of the models comes in. You can basically send it a frame of the video with the question “is this the review graphic for X movie.” The only problem is that it can add up quickly, since we don’t know exactly when each movie review graphic starts, we just know it happens at the end of the video. If we take one frame per second for the last 5 minutes of the video and send it in, that could work but it would be 300+ requests for each video. So you could do this with a cloud frontier model like Gemini but I wanted to try a locally running model.
I used Qwen2.5-VL 7B https://github.com/QwenLM/Qwen2.5-VL locally running on a 4090 using Ollama. I tested with 32B parameters and while it fit into memory the prompt response took 15-20 seconds, the 7B model is 1-2 seconds on this setup and got good results. I found that to get the model to verify what it is looking at you need to know how it would “describe” it, specifically what words it would use. So before I started I asked the model to describe samples of each summary card and then used that verbiage in the prompt. There were several iterations of the show and each time they changed the way the final thumbs up/down graphic looked. You can see the script here that uses FFMPEG to extract frame-by-frame and send it to the model to check. Here is an example of one of the prompts:
Does this image from the *Siskel & Ebert* show match this description:
"A review graphic with a thumbs-up or thumbs-down silhouette, the text
that could be a movie name, a possible still from the a movie, and the
text 'Gene' or 'Roger'".
"R" or "PG" or "G" or "PG-13" or "X" or "NC-17" are not movie names,
they are ratings.
If the name of the movie is visible, include it in the response.
Respond in valid JSON in the format:
{
"is_review_graphic": true/false,
"movie_name": "<movie_name>",
"reasoning": "one sentence explanation of why it is or isn't a review graphic"
}
This would produce a pile of frames that match the conditions that can then be refined down to match the review card to the movies I know were discussed in that episode from the transcript analysis. The “reasoning” value helped here in understanding why the model did or did not select an image. For example I found a false positive where it said its reasoning was that the movie name was “PG-13” so I added a part to the prompt to prevent that.
‼️ Takeaway: Smaller vision models can successfully be used to identify and extract metadata from images/video frames. You should get a base line description of how the model describes what you are looking to extract to better phrase the prompt. And you should include a “reasoning” response from the model to trouble shoot and refine the prompt further.
You could argue a more specifically trained machine learning computer vision approach to this problem would be faster/better, something like this project. But I found the model was able to often extract the title of the movie from the review card image most of the time. These titles were in various fonts and quality, so you definitely get more for less effort but of course the trade off might be reliability.
I did run into a problem with the review card graphics becoming more elaborate as the show aged, they introduced transitions, fading of one movie to another and the fade in of the thumbs up/down:
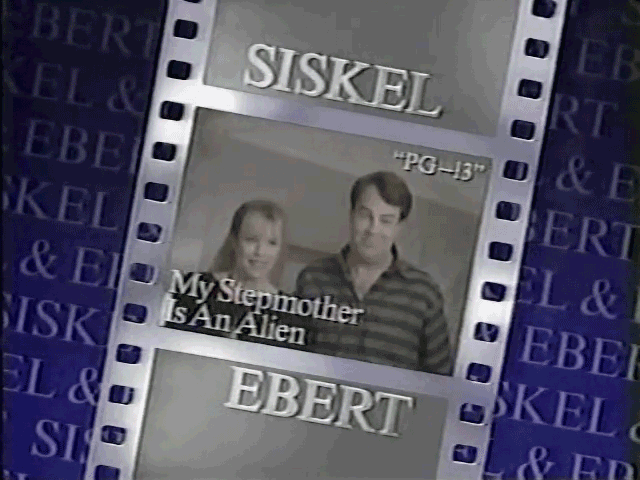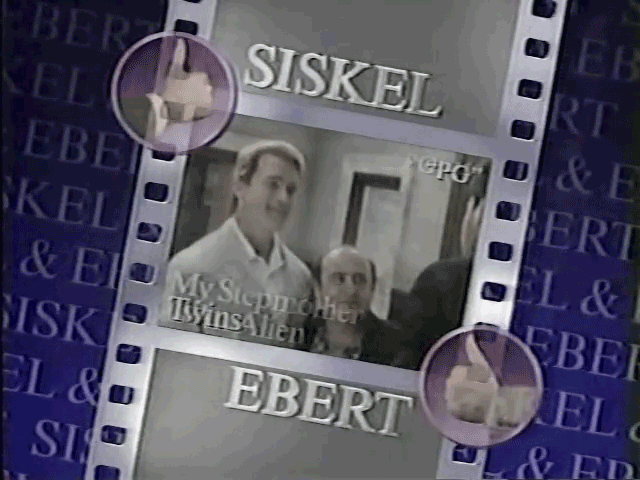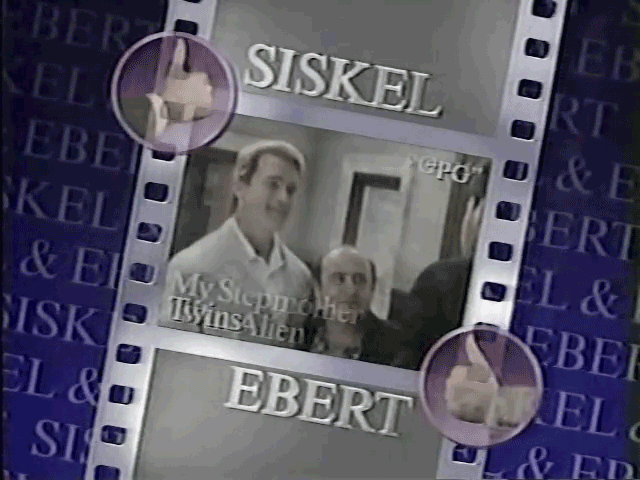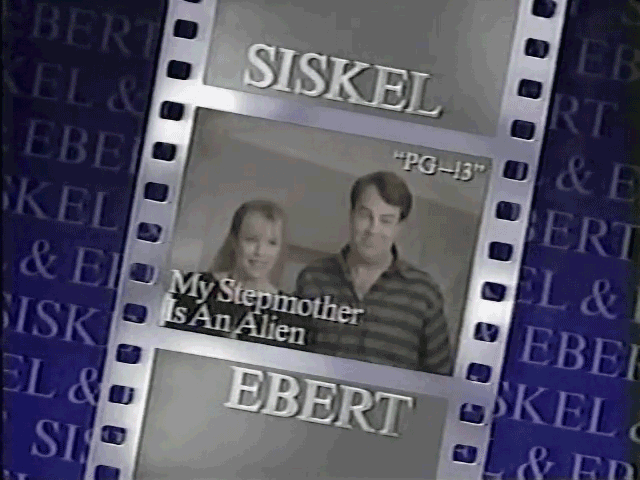
I had multiple images that represent the review card but I wanted the one where the thumbs up/down are clearly visible and not transparent mid-transition to the next movie. To do this I used Gemini2.5 to evaluate the image to test for any problems. You can see the script and prompt here.
Seeing how easy it is to send these images + metadata through the cloud models I wrote a couple QA scripts that double checked things with a final one that validates the image looks good and is for the right movie.
‼️ Takeaway: I think these models could be equally/more useful for QA workflows and other metadata checks as opposed to creating new metadata.
I then prompted Gemini to write a python script that builds a review page for all the images that the QA process flagged as wrong. It’s a simple static page that lets me quickly review the output.
‼️ Takeaway: You can use "vibe" coding to quickly build one off interfaces for QA review based on what the task is. I can customize the interface/fields but still not have to write a script that will only be used once.
I now have all metadata for each movie and the correct review graphic card selected the next step is to reconcile the movies to an authority. Any dataset should be reconciled if possible, something like this is really easy to match movies to their authority especially with the metadata we have already. I reconciled against Wikidata. Here is a script showing that process using SPARQL endpoint with their mwapi:search full text search service built in. The process also reveals issues and inconsistencies with the data form movies that fail to reconcile.
I pull data from Wikidata and populate a final dataset, over 2000 movies: https://raw.githubusercontent.com/thisismattmiller/siskel-and-ebert/refs/heads/main/final_data.json.
With the dataset created and assets extracted, I really can't help myself but to build a Bluesky bot: https://bsky.app/profile/siskel-ebert-bot.bsky.social
And why not stich them all together by year and movie name into a 1 hour 40 minute montage: https://www.youtube.com/watch?v=hFLMR26dZiA
It will take a few years for the bot to get through all the data. Again, not a very “serious” dataset or result but I learned a lot on how these types of models can be used and what kind of workflows they can assist with.
Final takeaways:
- If possible use a local model to reduce the size of the task and then use a frontier model to validate/finalize.
- These processes should be used more for QA and validation. I’m interested in looking at that more, why not have a process running through existing records checking for specific errors?
- A lot of these tasks are too qualitative to be done by traditional computational approaches, so I do see the value of these models. It is just a different way to work, emphasis on validation, double checking, QA, etc.
Code and data at the repo: https://github.com/thisismattmiller/siskel-and-ebert