Using GPT on Library Collections
Use cases for applying GPT3/3.5/4 on a full text collection
March 30 2023
- Intro
- Ground Rules
- Domain - Susan B Anthony
- Comparing GPT3 / 3.5 / 4
- Provenance
- Don’t call it Boutique
- Scale vs Voltage
- Should you use GPT?
- Conclusion
Intro
Here in early 2023 the breathless hype surrounding ChatGPT/GPT4 is honestly reaching annoying levels. On twitter every would be tech influencer Nostradamus is posting a screenshot of some tiny conversation they had with a computer and predicting the death of an entire industry. In the replies if someone offers the slightest pushback they counter with “Well, imagine what GPT-5 will be able to do!!” These folks are already living in the future where GPT is turning napkin drawings into websites and “changing the course of humanity.”
But maybe there is something here, if we dial the hype down and abandon the absurd notion of artificial general intelligence and apply GPT as the tool it is, a Large Language Model (LLM) designed to manipulate language. I work in libraries, which have a lot of language that could be manipulated, usually in the form of metadata, but more increasingly in the full text content of resources, books, articles, archives, etc. Let’s take a look at what sort of workflows could be built using this technology in libraries and archives to facilitate access and discovery.
And while I’m not a machine learning expert I understand the basics and can push data through an API. That makes me qualified to build these little demonstrations and talk about possibilities. It doesn't make me qualified to speak comprehensively on AI. There are a lot of reasons why you would not want to use this tech in this domain, especially OpenAI’s GPT, we will touch on some aspects of it but there is a much larger conversation that you should consider that I won’t be able to discuss fully.
Ground Rules
I reject using GPT to generate “answers” that did not come from a supplied text source. I’ve seen a lot of librarians on social media telling stories of them frustrated at failing to locate a requested resource only to learn that the patron got the citation from a ChatGPT conversation. Meaning it simply invented a convincing looking citation to a non-existent book or article. But we can use this LLM to manipulate existing text, that leads to a few ideas of how to use GPT:
- To arrange text based on context, aka layout detection.
- To summarize text
- To extract metadata fields from unstructured text
- To group similar text together to enable search
For these workflows that means all GPT operations must stem from an original text source. And while the results are very black box-ish they are never completely from thin air, you can trace the operation to the source.
Domain
Let’s take a look at some use cases. For these demos I used a collection housed at the Library of Congress, the daybooks, correspondence and writings of Susan B. Anthony. This archival collection was digitized and then transcribed by the “By the People” crowdsource platform. This is unusual in that while everything in the library is described at some level a very small portion of materials are digitized and even less are perfectly transcribed. But holdings at libraries and archives are extremely heterogeneous! While these demos are based off of very good source materials there is no lack of full text resources at the library even more so as an increasing number of resources are born digitally.
If we look at the daybooks there are many years worth of daily activities. The digital captures of the items look something like this:

And you can see the corresponding transcribed text. The potential usefulness of applying these techniques to materials like this is not about providing access, which the digital scans and transcription are doing but increasing the usability of the materials. For this we have to interact with the content of the resources and add context to the data. For me this crosses some line in my mind, from providing access to contextualizing resources. We’ll touch on this more later but for these examples we are going to apply this methodology to improve usability of these resources, which at this point in their lifecycle now consists of large unstructured blocks of text.
For the daybooks I wanted to get the data into blocks that have metadata about each one. So it should have a date of the journal entry, the people mentioned, where it was written, places mentioned and a quick summary of the entry. I ran each resource through the API with my prompt and it returned structured data that looks like this:
{
"placeWritten": "Toledo",
"dateFormated": "1871-02-11",
"dateOrignalText": "FEBRUARY 11 Saturday",
"fullText": "Left Toledo for
Iowa - N. Western R.R.
Went to Junction & thence
to Des Moisnes - Took
Omnibus to Mrs
Savory's - Found
both Mr & Mrs S. out
for the evening - but
soon they returned
& gave me a
most hearty
welcome - right
royal are they -",
"geographicalLocations": [
"Iowa",
"Junction",
"Des Moisnes"
],
"people": [
"Mrs Savory",
"Mr Savory"
],
"summaryText": "Susan B. Anthony travels from Toledo to Des Moisnes, Iowa and is warmly welcomed by Mr. and Mrs. Savory."
}
I will point out perhaps unobvious but seemingly impressive things that have happened:
- It has organized the blocks of text into two separate entries (the other entry for the 12th is omitted from the JSON data here)
- It isolated the text that belongs to this date.
- It has extracted a structured date from the textual date, which has a wildly varying format throughout the entire corpus.
- It has picked a context for where this journal entry was created, you could argue if it should have picked Iowa instead.
- It has done some entity recognition and extracted people and places.
- It has summarized the journal entry.
Any one of these operations would be fairly complex task on their own but we are able to accomplish all of them using GPT3.5 and this prompt:
“You are a helpful assistant that is summarizing and extracting data from a journal
written by Susan B. Anthony in {RECORD_DATE_HERE}. You only answer using the text
given to you. You do not make-up additional information, the answer has to be
contained in the text provided to you. Each page is a diary entry or financial bookkeeping.
You will structure your answer in valid JSON, if there are any quote marks in the
content escape them as ".”
“If the following text contains multiple journal entries, extract each one into an array of
valid JSON dictionaries. Each dictionary represents one of the entries, extract the date and
the date again in the format yyyy-mm-dd and the city or state it was written in and other
geographical locations mentioned that entry and people mentioned that entry and the complete
full text of the entry and a one sentence summary of the text, using the JSON keys dateText,
dateFormated, cityOrState, geographicalLocations, people, fullText, summaryText: {FULL_TEXT_HERE}”
You will notice the prompt is very heavy on trying to prevent the model from generating unrelated text from what was supplied. This worked mostly but will see an example where it could go wrong later. The result of this operation is a JSON dictionary for each entry found in the text.
The dataset is useful, what is good about this approach is that it is mostly repeatable across any source corpus. It is just arbitrary values extracted into a JSON object. The keys could change at a whim, for example asking for the names of plants mentioned instead of people mentioned. You could easily modify that prompt to do something similar to a completely different resource.
Since we have this mostly uniform in structure datasource we can build a simple interface on top of it:
Daybook Interface
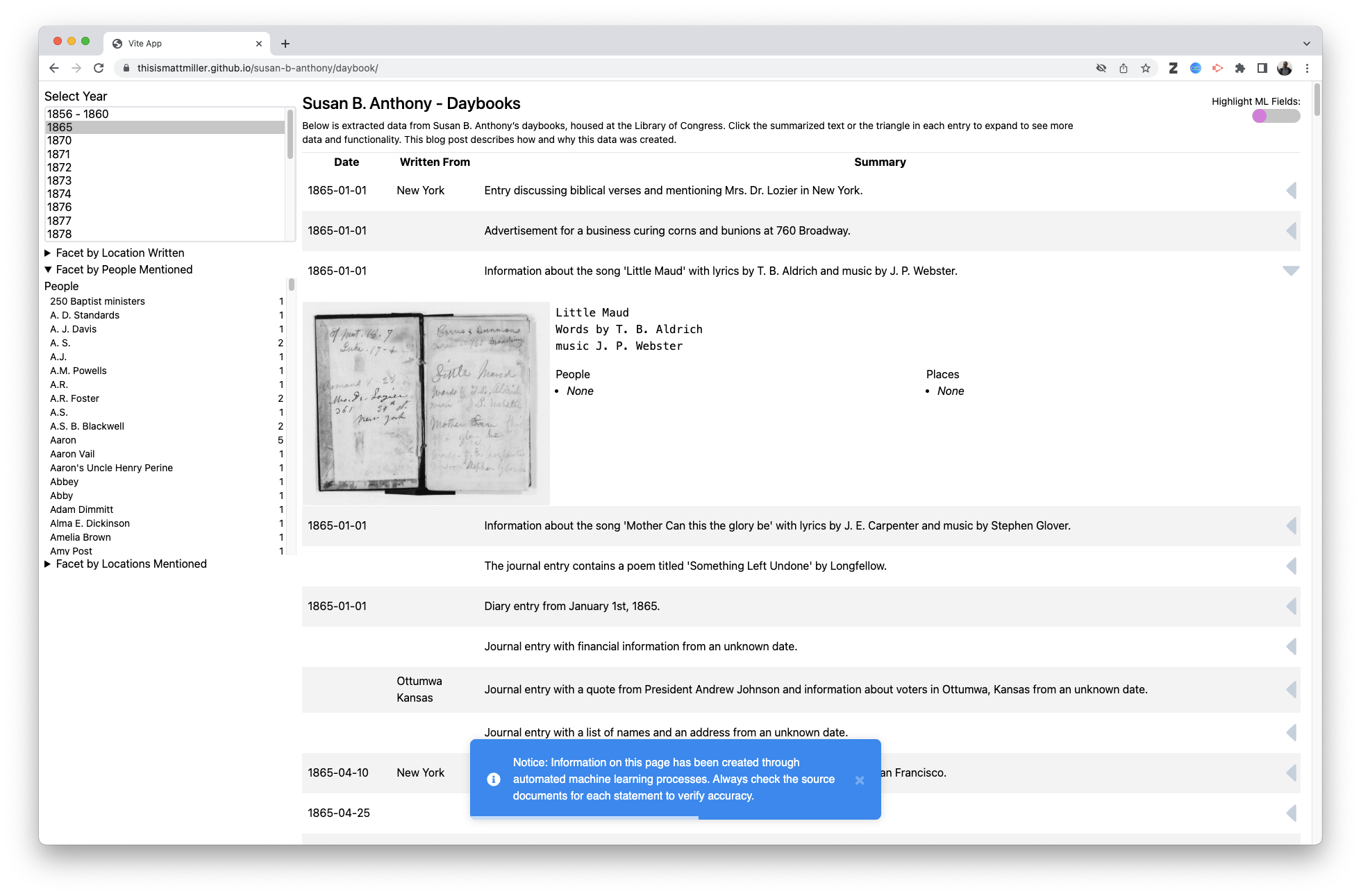
A very traditional but reusable layout with facets, and expandable content. As I mentioned earlier it is important to me to show where the data came from which is both actionable and advisory. So it shows a warning that content was created via machine learning processes and you can toggle a switch which shows how each field was created.
I’ve also left the data un-massaged, especially the facets, where it would be trivial to merge names based on punctuation or other common approaches. The only post-processing I did was to validate and fix any broken JSON, as sometimes the process will leave off a comma or something won’t get encoded and the JSON structure needs to be corrected before it will parse. I could imagine a host of post-process workflows around reconciliation linking to improve data quality.
Outside the extraction and summarization of the text this process has also ran the content through the OpenAI embedding API which generates a long vector representing the text as the model parses it. These vectors can then be compared to find text that is similar to each other. This can be kicked off by examining the whole entry to all the other text in the collection (daybooks, correspondence and writings) or you can highlight arbitrary text and see entries that are similar. This video demos how to do that:
What is interesting about this collection wide “Similar” search is that it will match the same words but it will also find contextually similar values. For example in the video above we see a search being done for the text “Political Equality Club” the top hits are other daybook entries that contain those words, but after that we get entries that mention “American Equal Rights Association” and other related concepts. There is no “understanding” going on here on GPT’s end; it is just that these values occupy similar spaces in the model.
I think the embedding search is a powerful addition to full text traditional search and perhaps a little more interesting than trying to search simply on occurrence of words. Though as will most GPT interaction the making sense of the output falls to the person, and we are very good at seeing connections, even if unintentional on the model’s behalf. And while an institution wide embedding search would require considerable resources this sort of collection wide similarity searching is easy to implement by storing the similarity scores in files and using server-less computing service to call up those indexes on demand to perform a query.
The other interfaces are variations on this theme, to prove a point of reproducibility. The content goes into the prompt and out comes a JSON response with some keys, which keys don’t really matter, whoever designs the prompt would decide what sort of data to extract based on the content.
Correspondence Interface
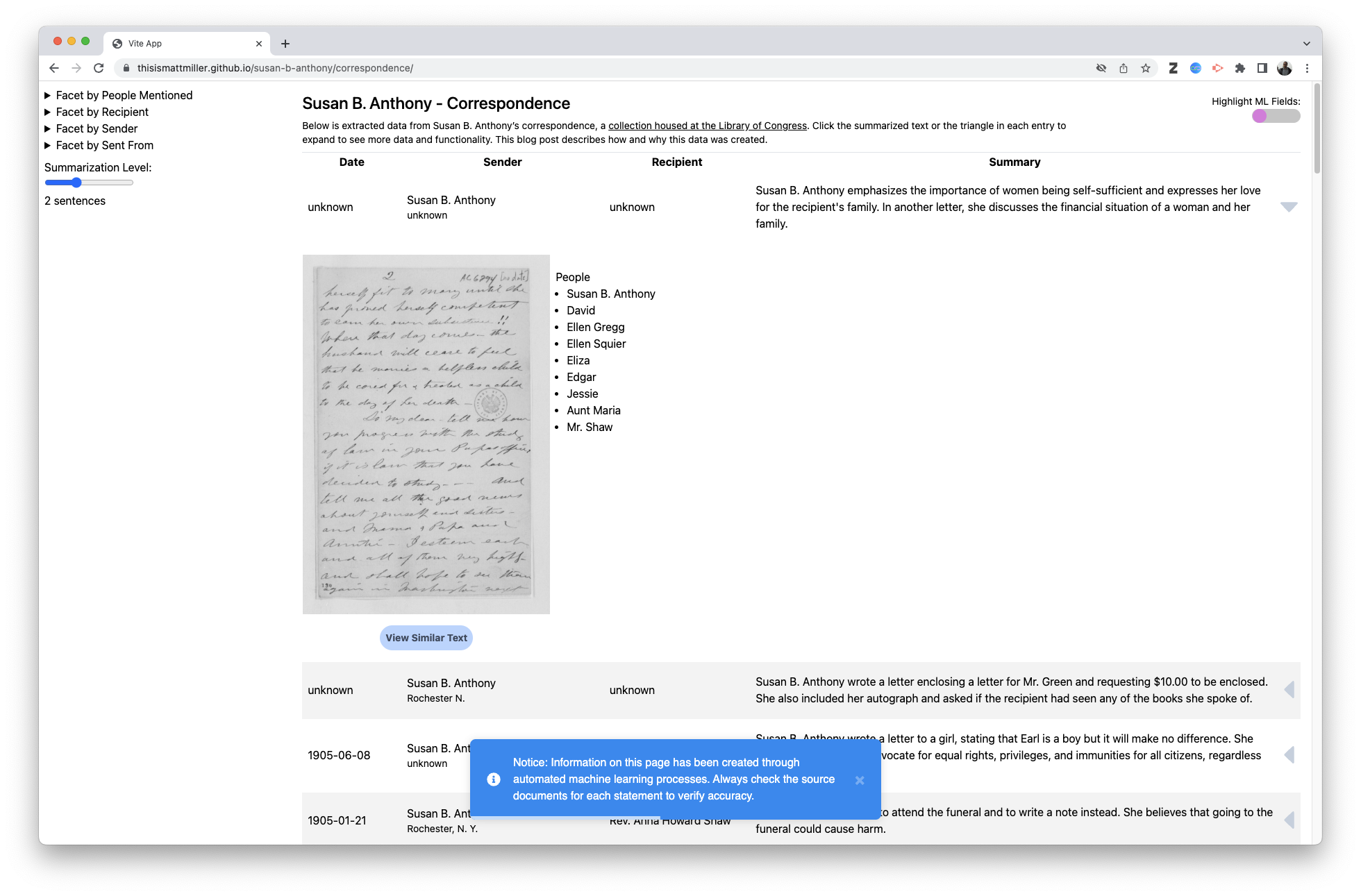
The correspondence interface also plays with the idea of summarization in addition to the facets. This would need to be user tested but the idea is based in traditional archival practice of description and arrangement. A finding aid is a summarization of the contents, some aids are very terse with only a collection level description, some are more descriptive going into series and subseries levels and some well funded finding aids go into detailed item level description. I’m curious about the idea that different level of summarization could facilitate different methods of discovery so this interface allows you to customize the depth of the summary:
The next interface displays the original writings and speeches of Anthony, I decided not to try to extract arbitrary fields in this group of documents and try another use case where the user is looking for references to ideas described in the speeches in the other parts of the collection. You could of course extract whatever concepts you wanted from each speech and facet them, I just did not think of that as very compelling. I’m not sure if the similarity search adds much to this corpus but I think there is potential.
Writings Interface
The last interface I have is just comparing the output from three generations of GPT models. This project took a while, over the course of about a month only working on it a couple hours here and there when I had time. In that span I began with GPT3, shortly after I started GPT3.5 came out and then GPT4 all within the time I was working on this. So I made a little grid to compare the output for daybooks. It’s hard to see a pattern of one mode being much better than other, also due to the non-deterministic nature of these processes it makes it hard to compare. It also serves as a quality assurance. The one thing I was afraid of was the model generating gibberish and populating it as if it was extracted from the document. I looked at example after example improving the prompt to prevent this from happening. But regardless it did occur at least once that I found, here is the compare grid for the 3 models:
Compare Interface

In this instance the entry was blank, meaning there was just a date, GPT3 and GPT4 correctly parsed this as an empty entry and did not extract anything. GPT3.5 aka chatGPT decided to invent a journal entry as if it was written by Anthony, a sort of deal breaker error in my opinion. This is the worst possible thing that could happen by generating false noise into the dataset. But I think you could easily mitigate these sorts of issues with a data quality check that compares extracted data to the original using simple methods like levenshtein distance and other approaches to make sure the data extracted is similar enough to the original and flag any issues.
Provenance
This data generated exists in a kind of gray space, it is generated by a possibly untrusted process. We have had and accepted processes similar to this in libraries and archives for a while though. OCR techniques for example that are often bad or faulty, populating incorrect text representations of a resource. But those types of errors seem more forgivable, they don’t cross what I mentioned earlier as the context line. An OCR process turning the word “of” into “at” is a lot different from GPT potentially incorrectly misrepresenting a historical correspondence. So the mind turns to mitigation, warnings and disclaimers. While working on this I’ve seen multiple people talk online about needing some way to tag data relating to machine learning. I saw this tweet by Shawn Averkamp (who has worked on machine learning processes in cultural heritage crowdsourcing) talking about flagging content from being included in training models. That also made me think about flagging content to users which I’m trying to do with the interface warnings and being able to highlight where the data came from. Of course we need metadata elements and machine readable vocabularies to also markup this data as well. I wonder if an organization is fine with crossing this context line and generating this type of data to aid in access and discovery how is that uncertainty communicated to the user? It seems that information literacy around recognizing AI generated content is a growing concern and it might be that it becomes a normalized skill and simply providing transparency is enough. You could also be very justified to refuse to cross this context line and make policies that exclude or prohibit any machine learning generated content in your systems.
I also think about the worries around machine generated content destroying the foundation of the internet. The concern being with so much bad content the whole system becomes unreliable at best and useless at worst. But I wonder if there is a flip side to that, if you use these processes to generate extracted data that is accurate to the source material you are putting positive data into that ecosystem. By transforming these cultural heritage resources into these accurate but derivative forms it’s as if they are vibrating at a different frequency. Perhaps these new forms are easier to index, discover or be included in these global systems.
Don’t call it Boutique
I’ve tried to emphasize that these processes are not one off things akin to a digital humanities project. I specifically did not do DH things to this data, I could have easily made a timeline or a map or something. But I don't want to give the impression that this is something specific to the Susan B Antony collection. I also want to point out why this might be different from previous computational workflows that have existed before now. For example, named entity extraction and other natural language processes have existed for a long time, why hasn’t that become a common thing as OCR has been appearing in library or archive records? This LLM approach is different in that you can easily change the output parameters on what you want to be in a dataset. You don’t need large technical knowhow to get different things out of the dataset, it's kind of a swiss army knife limited to what you think is useful. I could see a possibility where these workflows are operationalized to generate these derivative datasets as easily as OCR or other secondary data is published today.
There has also been a drive in cultural heritage to make things “Work like Google.” I can’t tell you how many times I’ve heard someone in libraries say “The patron just wants a google search box, that’s it!” when discussing discovery systems. I always thought that was absurd, but I wonder now that Google has become terrible at finding things in the last couple years if those people still feel that way. It makes me wonder while we're at an obviously important transition with the introduction of this technology if there will be a shift from the “flatten everything and put it in one big index” mindset toward more contextual and nuanced forms of search and discovery.
Scale vs Voltage
Relatedly I’ve thought a lot about the idea of “scale” which is connected to the idea of operationalizing something like this. I don’t really like this term, I don’t really know what it means besides someone trying to convey that they are “serious” about doing something. “Does it scale” is a tech meme concept that tries to convey competence. But pretty much anything can scale and then fail. Economist John List has this notion of “High voltage” and “Voltage drop”, where an idea could be a really exciting high voltage idea but when applied to a larger context doesn’t work. The voltage drops and it doesn’t apply beyond the original success. I’ve seen a lot of high voltage ideas around machine learning and GPT especially, which I think very easily fall into this paradigm. These ideas seem great on an individual case but do not “scale” to the larger context. Especially in cultural heritage I would say you are going to see a lot of machine learning ideas that are high voltage but will almost certainly experience that voltage drop if scaled up.
Should you use OpenAI GPT?
- Access to state of the art model, probably better than one you have access to otherwise
- Can be inexpensive, for GPT3.5, it costs about $0.20 to parse one of the daybook journals.
- Removes a lot of knowhow needed to get a model working correctly and producing useful results.
- OpenAI will block anything its overly greedy model deems offensive. For example in one journal entry Anthony wrote about a rainy day being “sloppy” and the boys and girls forgetting their “rubbers” a19th century vernacular bridge too far for this tool.
- Can be very expensive, GPT3 and GPT4 API are cost prohibitive. The same daybook that cost 20 cents in GPT3.5 would cost $5-10 in GPT4.
- It is an API, you need to make an API call every single time you want to do something like an embedding search. (You can store the embeddings of the documents, but you need to make the call to convert the query into a embedding so you can search the cached embeddings) It is pretty bad to depend on an 3rd party API to work in order to search, but library’s depend heavily on vendors anyway. I’m sure a vendor will supply this functionality in their future products that will simply be calling OpenAI APIs behind the scenes anyway…
- OpenAI seems like they are not following the ethos they started out with.
- OpenAI seems like they are now hiding how the model is trained and on what, which is bad.
- OpenAI probably has very bad ethics around how they hire people to curate and train data, similar to every other tech company.
- You should probably read very valid and nuanced critiques by AI ethicists who know what they are talking about.
Conclusion
If you are able to establish robust guardrails, these LLM processes seem like a very powerful way to manipulate metadata and content in a cultural heritage context. Often the data we process is too complex to easily work with via traditional programmatic approaches. I could see using this tool to easily create derivative datasets from the large amounts of data libraries and archives hold. Though, if embraced, institutions would need to clearly communicate the process that created them which are both human and machine readable.
Code: https://github.com/thisismattmiller/susan-b-anthony
Related Posts: