WoodBlockShop
Using Segment Anything, LLaVA and other methods on a 14K image corpus
Dec 16 2024

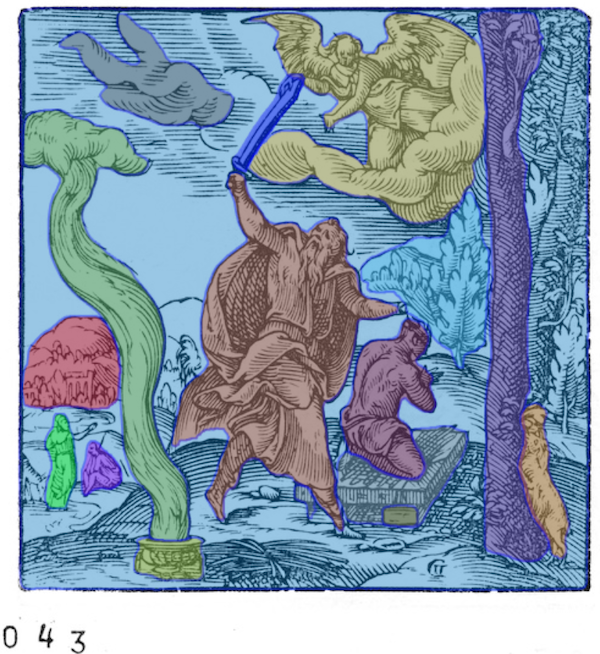
I came across people sharing the Plantin-Moretus Museum collection site and I really liked it. The 14,000 woodcuts are obviously all very different but the monochromatic cohesion of the collection ties it together. I thought it would be a great collection to try some of the various image based machine learning techniques I’ve seen recently. Specifically I wanted to try the Meta Segment Anything 2 model on it thinking it would be very cool to break down some of the very dense but simple prints into component pieces to do something fun with.
Having been a laptop loser for the last 15-ish years (still am tbh) I built a new computer this summer. I haven’t put together a computer since my early 20s but it went pretty well. I specifically put a nice Nvidia card in it to try some local machine learning stuff. The card is more of a gamer card but with 24GB of VRAM it can still run a lot of models in memory. To get the models working I ran Windows to get the Nvidia drivers and cuda toolkit installed and working easily, then used Windows Subsystem for Linux which lets you have a linux environment within windows which makes using it tolerable.
Getting the corpus was pretty straight forward, the site has a nice JSON search index. I downloaded all the images, I used the “thumbnail” version of the images for my project, while they have very large hi-res tiffs available I didn’t use them. Most of the almost 14K images are a few hundred kilobytes, none larger than a megabyte.
You probably saw the Meta Segment Anything demo site it is super impressive. Specifically the ability to do automatic masking (as opposed to defining a specific target region) and basically have it pick out prominent features and build masks which lets you extract the sub-images. If you use the demo site it does a great job so I started running my woodcut images through the SAM 2.1 Hiera Large model. I asked it to use its automatic mask generator to pull out features. And it worked terribly compared to the demo site. So I spent a couple hours tweaking the parameters and it got better but nowhere near as good as the demo on the Meta site. Here are some comparison images:


{kind=link}